Fra scienza, verità e Sangiovese
Molti non hanno capito Kary Mullis e la sua genialità, genialità che si esprimeva nell’acutezza delle sue osservazioni e che lasciava poco spazio a speculazioni equivoche. Il vero scienziato, termine ormai abusato da molti, non scende mai a patti, anche con l’amico più caro ma cerca di capire finché la verità non appare limpida e inoppugnabile

Eravamo molto vicini a quel magico 2008 (leggi: Parlare di scienza al Bar, Olio Officina) quando passai mesi di angoscia in attesa della risposta di Kary alle dinamiche della ricerca che legava Piastrine, Acidi Grassi, Psicopatologia e Cardiopatia Ischemica.
Come al solito, l’incomprensione che ci fu fra Kary e me trovò giusta collocazione in un pomeriggio a casa di amici dove il bottiglione di Sangiovese che avevamo davanti scendeva vertiginosamente di livello man mano che si discuteva, e animatamente.
L’amicizia, per fortuna, quella vera non lascia mai spazio a risentimenti né momentanei né duraturi.
Quando lasciai Kary in albergo ci abbracciammo fraternamente, un conto è l’amicizia e un conto è la verità scientifica.
Il vero scienziato, termine ormai abusato da molti, non scende mai a patti anche con l’amico più caro ma cerca di capire finché la verità non appare limpida e inoppugnabile.
Da quella famosa bottiglia di Sangiovese, passarono diversi mesi e la mia angoscia saliva giorno dopo giorno in attesa della risposta di Kary.
Se fosse arrivata una risposta negativa o dubbiosa sulla ricerca avrei rinunciato a tanti anni di lavoro cancellandoli dai miei pensieri perché ero certo che Kary non poteva sbagliare.
Certo, il primo approccio alla discussione, come si legge più avanti, fu durissimo, drammatico, devastante e sarcastico.
Molti non hanno capito Kary Mullis e la sua genialità, genialità che si esprimeva nell’acutezza delle sue osservazioni e che lasciava poco spazio a speculazioni equivoche.
Oggi sono e sto scrivendo di fronte al mare del golfo di Solanto (come lo chiamo io), in Sicilia.
La schiuma d’onda si rincorre in modo cadenzato e perpetuo per infrangersi sulla scogliera che sta sotto al terrazzo di casa, e assomiglia molto ai miei pensieri del tempo, arrivavano continuamente e temevo che, come la schiuma d’onda, si frangessero su un pezzo di vita dedicato alla ricerca e alla sua verità.
Leggendo le parole che seguono si capisce come le onde non si sono infrante ma hanno consentito la forza di andare avanti. Il mare delle idee, nella scienza vera, non deve mai infrangersi contro nessun ostacolo.
Corrispondenza con Kary Mullis (2007)
Kary Mullis a Massimo Cocchi
… ho pensato molto al nostro problema cercando di capire perché non riusciamo a capirci. Non sono sicuro che quanto, ora, scrivo sarà di aiuto, ma forse è qualcosa di utile per chiarire la mia posizione:
Sulla questione delle reti neurali proviamo ancora una volta, Massimo, perchè da qualche parte ci deve essere un’incomprensione nel nostro dialogo sul problema di una rete neurale non addestrata, capace di individuare la possibilità di patologia coronarica cardiaca in un insieme di pazienti, quando la sola informazione data alla rete è la concentrazione di tre grassi (chiamiamoli 1, 2 e 3) sulle loro piastrine.
Quello che ho capito è che stai dimostrando che, in assenza di un set d’addestramento, il tuo programma riesce a individuare i pazienti che hanno un’alta probabilità di sviluppare problemi coronarici solo da questi valori.
Per set d’addestramento intendo che i valori per 1, 2 e 3 accoppiati con una diagnosi indipendente dell’esistenza di problemi coronarici arteriosi vengono presentati al computer in un certo numero di casi del tuo gruppo iniziale.
Tu stai affermando che non è necessario un set d’addestramento. Io chiedo, com’è possibile che funzioni?
Ora, io mi rendo conto che la composizione lipidica sulle piastrine possa facilmente avere qualcosa a che fare con i problemi coronarici alle arterie (e con la depressione clinica).
Io non sono perplesso che lo possano, non l’ho mai sentito dire da nessuno, ma quando mi hai detto che era vero, l’ho accettato.
Ma quando mi hai spiegato che il tuo programma ha scoperto questa relazione senza alcun riferimento a standard esterni, a un qualche set d’addestramento, sono rimasto incredulo e tuttora lo sono.
Io affermo semplicemente che, senza altri dati, come quelli di un set d’addestramento in cui le variabili dei lipidi siano accoppiate con diagnosi cliniche, o delle variabili simili, note e legate a problemi coronarici arteriosi (o con una conoscenza straordinaria di fisiologia), la rete neurale, che è un oggetto matematico, non un oracolo, non può sapere nulla sui pazienti se non i valori 1, 2, e 3 (gli input).
Nella mia esperienza, di solito, gli input delle reti neurali, addestrate con dati noti, sono basati su qualcosa come un migliaio di concentrazioni Rna [nel senso di Acido Ribonucleico, n.d.r.] forniti da centinaia di pazienti, così tanti dati che i ricercatori avrebbero difficoltà a vederne le connessioni, quindi la necessità di utilizzare subito il computer.
Poi, se la relazione che scoprono è semplice come quella di una qualche espressione matematica tra tre numeri, certo tutti rimarrebbero sorpresi, ma il programma per computer non sarebbe più necessario in seguito.
Lo scopo del computer era trovare quei tre particolari parametri in mezzo a migliaia disponibili.
L’analisi di una particolare scoperta clinica in quel caso può, quindi, essere fatta inizialmente con un calcolatore, per proseguire senza.
Qualcosa di simile è accaduto in una società di cui ero consulente in Savannah: una semplice soluzione a un problema di diagnosi differenziale di leucemia linfocitica acuta e leucemia mieloide cronica apparve utilizzando un programma per computer chiamato Support Vector Machine.
Lo input era composto da diverse migliaia di livelli di Rna ottenuti da diverse centinaia di pazienti.
Una volta ottenuto il risultato chiarificatore non ci fu più bisogno di un computer per fare la diagnosi.
Un ricercatore avrebbe anche potuto osservare non più di due livelli di Rna rilevanti per volta, e poi ricominciare le osservazioni. Fino a quel momento non era noto quali dei due avrebbe contenuto la soluzione, o se ci fossero solo quei due livelli di Rna che la contenessero.
La Support Vector Machine fu quindi “allenata” con i dati clinici, non solo con i livelli di Rna.
Ecco perché il tutto ha funzionato. I computer sono in grado di sviluppare pazientemente noiosi calcoli, ma non sono in grado di dirci qualcosa che, pur con tanto tempo a disposizione e una pazienza quasi infinita, tu possa avere concepito fuori di te stesso su un calcolatore.
Non vi è alcuna discontinuità tra matematica classica e ciò che è indicato come Macchina di Turing, come calcolatore universale.
Sono solo veloci, molto veloci, ma non infinitamente veloci o saggi, che è la cosa ancor più importante. Ciò significa che abbiamo capito come funzionano, non c’è nessun mistero, solo la velocità.
Quindi, se il tuo programma è in grado di prevedere sempre le condizioni delle coronarie partendo da tre numeri che rappresentano il “dosaggio” di quei tre diversi lipidi sulle piastrine, senza dover mai essere addestrato su un insieme variabili associate con indicatori clinici, non c’è dubbio che un filosofo della scienza potrebbe legittimamente dire che tu hai scoperto qualcosa d’inspiegabile, ma chiaramente utile.
Tuttavia, la sua validità è puramente basata sull’induzione, sempre che Lucio non possa spiegare com’è successo, e che il processo possa essere adattato ad altre applicazioni.
La maggior parte degli scienziati, d’altra parte, e devo ammettere che anch’io ne faccio parte, direbbe che siete stati dannatamente fortunati o che avete omesso qualcosa d’importante.
Quello che stai facendo non è scientifico, nel senso comunemente accettato. È privo della qualità essenziale di essere in gran parte spiegabile come conseguenza, comunque sottile, di fatti noti, e quindi servire come guida agli altri scienziati per sviluppare metodi simili.
Se Lucio ha scoperto un nuovo principio sulle reti neurali che permette loro, indipendentemente da un set di addestramento, di distinguere arterie coronariche sane da arterie coronariche malate, in conformità a tre numeri, che per un computer non “biologicamente informato” sono solo numeri, quel principio fa compiere un balzo rivoluzionario alle nostre conoscenze in quest’ambito, e merita di essere pubblicato non solo nelle riviste del settore medico, ma anche sulle riviste d’informatica.
Ammettiamo che questo sia il caso, vuol dire che hai trovato nuovi principi di programmazione delle reti neurali. È stato scoperto e si sono trovate le ragioni per cui tre lipidi possono predire il futuro dei problemi cardiovascolari, le congratulazioni sono di rito, ma anche in quel caso, non capisco il motivo per cui il calcolatore sia ancora necessario per fare la diagnosi.
Nel caso in cui ho accennato in precedenza per quanto riguarda la leucemia, una volta che i geni rilevanti furono individuati, il programma informatico non fu più necessario.
C’è una spiegazione che posso immaginare per tenere conto dei fatti, ma mette in discussione le tue opinioni e quelle di Lucio.
Poiché sono state considerate solo tre variabili, non è impossibile che il rapporto tra loro, che si correla con la malattia coronarica, sia abbastanza semplice, e che avreste potuto scoprirlo empiricamente, senza l’uso di una rete neurale sia nella fase iniziale sia in seguito.
In realtà, quanto può essere complesso il rapporto fra tre numeri? Che cosa sta facendo il computer? Perché non si confrontano i tre numeri semplicemente guardandoli alla luce di quello che era un paziente a rischio coronarico? Che come te mi hai spiegato dai dati del Framingham era principalmente l’età dei pazienti? C’era qualcosa che t’impediva di conoscere il loro potenziale stato coronarico prima dello studio col computer, e, se è non così, come valuti i tuoi attuali risultati?
O tu conosci ora il rischio coronarico e puoi compararlo a quello che dice il tuo computer, o non puoi.
Se sai questo ora, è possibile utilizzarlo per convalidare il tuo risultato. Se lo sai adesso, quando l’hai imparato? Eri ignaro di ciò prima dello studio con il computer? Cordialmente tuo Kary
Ottobre 2007
Lucio Tonello a Kary Mullis
… Ora ho realmente capito (o almeno spero) il motivo dell’incomprensione tra te e Massimo.
Proverò a spiegarmi. Tu hai scritto che dobbiamo partire da un set d’addestramento, hai ragione: noi dobbiamo partire proprio da lì.
Forse questo è il punto centrale dell’incomprensione ma, credo che sia semplicemente un problema di termini.
Certo che siamo partiti da un set d’addestramento. Sull’Ischemia, è fatto di 60 soggetti sani contro 50 con diagnosi definita di Ischemia.
Quindi avevamo una base dati di 110 soggetti.
Per ogni soggetto avevamo l’insieme degli Acidi Grassi (11 variabili) accoppiato con una “variabile esterna”: lo stato patologico dal punto di vista ischemico, cioè se il soggetto fosse sano o malato.
Quindi, siamo assolutamente partiti da un set d’addestramento.
Io penso che l’incomprensione sia nata parlando del metodo matematico, in particolare del processo d’addestramento.
Molti metodi matematici, in particolare le Rna, vengono classificate in 2 grandi famiglie: le Rna supervisionate e le Rna non supervisionate, a seconda del processo di apprendimento che usano.
1) Le Rna che usano un processo d’apprendimento supervisionato, hanno bisogno di un set d’apprendimento completo, cioè di tutte le variabili più una “variabile esterna”. Per esempio, il Multi-Layered Perceptron (di solito usato con algoritmo di Back Propagation) è una rete supervisionata, probabilmente la più comune. Essa studia il Data Base, “apprendendo” le caratteristiche d’ogni soggetto, in funzione del valore della loro “variabile esterna”, che è nota. Dal punto di vista matematico, essa costruisce una superficie n-dimensionale dell’errore legando tutte le variabili coinvolte con la “variabile esterna”. È detta supervisionata perché si auto corregge riducendo, in modo iterativo, l’errore globale conoscendo il risultato corretto, come se un “insegnante” la correggesse ogni volta.
2) Le Rna che usano un processo di apprendimento non supervisionato, come la Self Organizing Map (Som), hanno solo bisogno di tutte le variabili, ma non di quella “esterna”. Questo perché usano un approccio diverso: non vengono addestrate per trovare le caratteristiche dei diversi valori della “variabile esterna”. Guardano solo i dati e provano a mettere assieme soggetti simili senza considerare alcuna “variabile esterna” (attenzione, le Som sono diverse dalla comune “cluster analysis”).
Una Som riesce a farlo, confrontando, alla sua maniera, tutti i soggetti del data base (se ti interessa, allego un’appendice nella quale provo a spiegare come lavora una Som ma, per favore, prima leggi questo foglio fino in fndo).
Penso che possa essere più chiaro se si segue questo esempio. Supponi di voler costruire un sistema capace di riconoscere lettere scritte a mano.
Probabilmente parti da un Data Base fatto di lettere scritte da persone differenti (ovviamente con diverse calligrafie).
In questo caso, la “variabile esterna” è la vera lettera dell’alfabeto che è rappresentata da quelle scritte a mano dello stesso significato.
Puoi costruire questo sistema usando un metodo statistico supervisionato. Ma puoi anche usare una Som. In questo caso, devi mostrare alla Som le diverse lettere scritte a mano, mescolandole e senza dire quali rappresentino la “A”, “B”, “C” e così via.
Devi solo sperare che la Rete ponga le diverse lettere in aree differenti, mettendo le lettere “A” scritte a mano vicine l’una all’altra, e lontane dalle lettere “B” e “C” scritte a mano e così via.
Se (come di solito succede) dopo che la Som è stata addestrata, tutte le “A” sono vicine, tutte le “B” sono vicine e così via, la Som è pronta: matematicamente capisce che le “A” sono simili e le mette vicine l’una all’altra.
La Som capisce che le “A” sono diverse dalle “B” e mette tutte le “B” scritte a mano lontane dalle “A” ma, ancora, vicine fra loro.
Anche in questo caso la “variabile esterna” è la lettera dell’alfabeto, legata alle diverse lettere scritte a mano.
La Som questo non lo sa, né in fase di apprendimento né in fase di produzione della mappa finale.
Solo dopo che la mappa è pronta, un osservatore esterno può notare che tutte le lettere scritte a mano legate alla lettera “A” sono insieme! E per le altre lettere è la stessa cosa.
Solo ora, l’osservatore divide la mappa in cluster, uno per lettera (di solito usando metodi matematici molto noti come la clusterizzazione di Voronoi).
Una volta che la rete è addestrata, se le diamo una nuova lettera scritta a mano, essa sarà mappata vicino alle lettere a lei più simili, molto probabilmente nel cluster corretto.
Quindi, tutto il set d’addestramento, in fin dei conti, è assolutamente necessario, ma non lo è per l’addestramento della Som.
A proposito, i comuni software commerciali Ocr (riconoscitori ottici di lettere) spesso usano davvero questo metodo.
Anzi, molti comuni software commerciali usano questo tipo di Rna anche per molti altri scopi.
Torniamo all’Ischemia. Avevamo un “insieme di addestramento” di 110 soggetti. Abbiamo dato alla Som il Data Base dei 110 soggetti, senza dirle quali fossero i malati e quali i sani (esattamente come per le lettere scritte a mano). Abbiamo dato alla Som solo i valori dei 3 acidi grassi.
Dopo che la Som ci ha dato il risultato (intendo la mappa), ci siamo limitati a osservare che i soggetti patologici erano tutti collocati nella parte alta della mappa e tutti i soggetti sani, nella parte bassa.
Ma l’abbiamo osservato noi, non la Som, che non conosceva il loro stato patologico.
Voglio dire: dopo che la rete ha disegnato la sua risposta, cioè la mappa, noi abbiamo colorato di verde i soggetti sani e di rosso quelli malati e abbiamo preso atto del risultato.
Poiché tutti i patologici sono in un cluster mentre gli altri in un altro, spazialmente opposto, possiamo dire: “Tutti i soggetti patologici sono simili tra loro, e diversi dai normali, almeno dal punto di vista dei 3 acidi grassi coinvolti”.
Questa ultima frase (chiamiamola frase 1) è assolutamente “scientifica”.
Infatti le Som sono reti neurali molto comuni, conosciute a fondo e molto usate anche in comuni software commerciali. Sono apparse alla comunità scientifica oltre 25 anni fa (T. Kohonen, 1981).
In ambito biomedico, le Som sono ampiamente usate da almeno 10 anni e, per certo, sono assolutamente accettate.
Dunque, il protocollo usato, non è un mistero, niente è quindi inspiegabile, ma tutto è ben conosciuto e accettato da anni. Forse non è comune come una regressione logistica ma, almeno qui in Italia, è più comune della Support Vector Machines.
Se qualcuno, ovunque e ogni volta che vuole, costruisce una Som o la compra (ci sono centinaia di software commerciali per sviluppare Som) e la addestra col nostro set d’addestramento (ovviamente senza l’informazione sullo stato patologico), troverà che i soggetti patologici vanno da una parte e i sani da quella opposta.
Probabilmente, non troverà esattamente la nostra mappa, ma di sicuro un risultato simile. Infatti, una Som, come quasi tutti le Rna, dipende da pesi iniziali casuali e da altri parametri: come sai, essendoti famigliari le Rna, ogni processo di apprendimento è sempre diverso da un altro! In ogni caso, se qualcuno usa gli stessi parametri che abbiamo usato noi (a dire il vero, sono quelli suggeriti dalla letteratura, quindi i primi che un informatico proverebbe…) otterrebbe la stessa mappa.
Come risultato della frase 1, possiamo aggiungere che le concentrazioni dei tre acidi grassi della popolazione patologica sono, in qualche modo, diverse da quelle della popolazione sana.
Un altro risultato è che, come nell’esempio delle lettere scritte a mano, possiamo mappare un nuovo soggetto, il cui stato è ignoto e, secondo la sua posizione nella mappa, secondo il cluster in cui è collocato, possiamo pensare che probabilmente può essere considerato sano o patologico.
Ad esempio: se la sua posizione nella mappa è in mezzo ad altri soggetti tutti patologici, si potrà sospettare che sia patologico anch’egli, o almeno è molto probabile.
Ora, a proposito della necessità di usare un computer nella nostra ricerca, occorre dire a nostra giustificazione che il nostro caso non era quello di scoprire relazioni semplici fra numeri, ma vi era un problema più complesso.
Nella nostra situazione, avevamo 110 soggetti e, per ciascuno, solo 11 variabili (accoppiate con lo stato patologico, la 12° variabile).
Quindi il nostro problema principale non era di trovare quei particolari parametri (1, 2, 3) tra gli 11 disponibili.
Parlando dell’Ischemia (le cose sono piuttosto diverse nella Depressione), abbiamo identificato i 3 acidi grassi, piuttosto facilmente, per mezzo della statistica convenzionale (Analisi Discriminante, Anova ecc.).
Una volta trovati i tre parametri, volevamo studiare la loro dinamica, volevamo più informazioni, una conoscenza più approfondita del problema, e, uno strumento diagnostico.
Allora abbiamo provato a usare diversi strumenti matematici come la Cluster Analysis, i Classification Trees e così via, ma, secondo noi, il migliore è stato la Som.
Infatti, ci ha condotto velocemente a molti importanti (secondo noi) risultati.
Noi non usiamo un migliaio di concentrazioni di Rna, ma una semplice Som.
Forse nel nostro caso, la necessità di usare un computer non è al primo posto, forse saremmo potuti arrivare allo stesso risultato “a occhio” ma, come dici tu, la principale caratteristica di un computer è la velocità e il nostro principale obiettivo era il risultato, il metodo era in secondo piano.
In ogni caso, a occhio non potevamo valutare i 3 parametri contemporaneamente con la stessa velocità e precisione della Som. Molte persone sono spaventate dal nome “rete neurale artificiale”.
Ma, le Rna non sono per niente oggetti strani! Non sono difficili, sono accettate come strumenti utili da anni e usate comunemente anche in applicazioni d’uso quotidiano.
Forse, l’unico problema è l’approccio che usano, un po’ diverso da quello della statistica convenzionale.
Ma, il problema, se esiste, è solo nel nostro modo di pensare. E, ne sono sicuro, Kary, tu non hai certamente questo tipo di problemi!
Un’altra tua domanda: “C’è una spiegazione che, immagino, spieghi i fatti, ma mette in discussione la tua conclusione e quella di Lucio. Visto che si sono considerate solo 3 variabili, non è impossibile che la relazione tra loro, che le correla con la patologia coronarica arteriosa sia abbastanza semplice e che la si sarebbe potuta scoprire empiricamente senza l’uso di una rete neurale, sia all’inizio che, soprattutto, in seguito. Infatti, quanto complessa può essere la relazione tra tre numeri? Cosa sta facendo il computer? Perché non avete confrontato a occhio i tre numeri sapendo quali erano i pazienti a rischio coronarico arterioso (che come mi avete spiegato dai dati Framingham è molto correlato all’età del paziente)”.
Beh, non è necessario un computer per indovinare una lettera scritta a mano! Quanto complicato può essere riconoscere una lettera scritta a mano?
Ma, ti chiedo: riesci a spiegarmi le regole matematiche che permettono di classificare una lettera scritta a mano, in modo semplice?
O meglio: una lettera digitalizzata può essere espressa, per esempio, con una matrice di 8 x 4 = 32 pixel.
Certo, noi possiamo dare una formula con 32 variabili che classifichi un carattere, ma tutti gli informatici troveranno più agevole usare una Som invece di una formula.
E io sono d’accordo con loro.
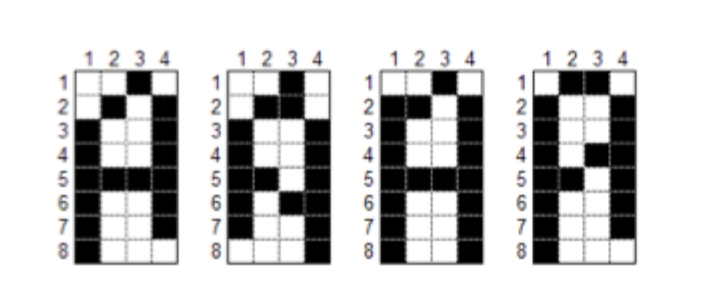
Nel nostro problema, ci sono solo tre numeri, è vero.
Ma, quando abbiamo costruito la mappa della Som, abbiamo solo capito che usando 3 acidi grassi, potevamo classificare un paziente, ma senza assolutamente conoscere le regole corrette per farlo.
Abbiamo capito subito che non era un problema facile. Quando Massimo e io studiavamo “le regole”, osservavamo che un soggetto era patologico se il parametro 1 era basso mentre il 2 era medio e il 3 era alto.
Se il parametro 3 calava, il soggetto non era più patologico a meno che non crescesse anche il parametro 2, ma solo fino a un certo valore, e così via.
Intendo dire che ci sono molte possibili configurazioni e combinazioni.
Siamo d’accordo che avremmo potuto esprimere tutto con carta e matita, ma semplicemente troviamo più appropriato e chiaro usare una mappa bidimensionale, che a nostro parere è più semplice, facile e chiara.
Per esempio, pensiamo all’Indice di Massa Corporea (Imc) e alla sua applicazione, è una delle formule più semplici del mondo, devi solo calcolare Altezza/Peso2 e controllare il risultato su una tabella di riferimento.
Beh, ogni dottore ha uno stupido software che lo fa. Sono sicuro che potrebbe essere fatto a occhio, ma è più veloce e forse più facile usare un computer.
Certo, abbiamo tradotto tutti i nostri risultati in regole e che stiamo usando per continuare la nostra ricerca.
Ma quando dobbiamo controllare lo stato di salute di un nuovo soggetto, troviamo più agevole usare la Som, specialmente quando un soggetto si colloca nella nostra area border-line.
Quindi Kary, come hai visto non c’è mistero, niente d’inspiegabile.
Tutto è nel senso comunemente accettato: quello scientifico. purtroppo non ho scoperto nessun nuovo principio sulle reti neurali, sfortunatamente: la rete che abbiamo usato esiste dal 1981.
Tu hai dovuto parlare di problemi matematici con Massimo, che non è né matematico, né informatico! Forse la ragione di questa incomprensione tra te e Massimo, tra te e noi, sono io.
Mi sento davvero responsabile e ti chiedo scusa, perché non sono stato chiaro nelle mie spiegazioni.
Forse la ragione di questa incomprensione tra te e Massimo, tra te e noi, sono io: il matematico che avrebbe dovuto essere chiaro.
Mi sento davvero responsabile e ti chiedo scusa della mancanza di chiarezza nelle mie spiegazioni. …
Ti ringrazio del tempo dedicatomi, con affetto,
Lucio.
Kary Mullis a Massimo Cocchi
Caro Massimo,
Lucio mi ha chiarito la situazione. Ora capisco il vostro lavoro e concordo sul fatto che si tratta di un contributo, per il settore della diagnostica in cardiologia, che vale la pena sviluppare.
C’è stato un problema di comunicazione. Non ho capito che, dopo l’auto-organizzazione la mappa prodotta dal programma aveva operato in modo non supervisionato su tutti i dati di pazienti sani e a rischio, collocando ogni singolo set di valori per l’acido oleico, l’acido linoleico e l’acido arachidonico in una delle 400 caselle, secondo la somiglianza dei rapporti esistenti tra di loro.
Allora tu, sapendo (da considerazioni indipendenti) quali erano i set a rischio, hai “colorato” 400 caselle in base a “sano” o “a rischio”.
Quel tuo input ha sostituito la procedura d’informazione globale per cui essa ha gestito in un certo modo i valori originati dai pazienti sani e patologici, e una logica induttiva ti ha consentito di supporre che ogni qualvolta i futuri valori rientreranno in una delle due categorie, saranno significativi per il fine che ti proponi.
Certo, ora esaminando il programma che assegna le concentrazioni dei tre acidi grassi a particolari celle nel tuo programma, tu potresti sostituire il programma con una serie di “if then”, ma ho capito che i computer sono ormai onnipresenti e poco costosi.
Perché preoccuparsene.
Inoltre, continuando ad aggiungere dati che tu sai provenire da sani o malati, potresti raffinare i tuoi colorati valori, se questo sarà richiesto.
Quindi, il mistero è risolto. Mi dispiace di essere stato tanto apprensivo. Penso che se gli scienziati ancora rifiutassero di parlarsi l’uno con l’altro, se non in latino, certe incomprensioni non accadrebbero.
Ma allora dovremmo tutti imparare il latino (anche gli italiani), e metterci d’accordo su come interpretarlo.
Dai a Lucio tutta la mia stima e assicuralo che ora ho capito cosa stai facendo, grazie alla sua spiegazione. …
Cordialmente,
Kary
La foto in apertura è di Olio Officina©

Per commentare gli articoli è necessario essere registrati
Se sei un utente registrato puoi accedere al tuo account cliccando qui
oppure puoi creare un nuovo account cliccando qui
Commenta la notizia
Devi essere connesso per inviare un commento.